After six months of sacrifice and hard-work, I am proud to say I have completed the data visualization and analytics boot camp I was attending at the University of Minnesota. For my final project, I wanted to push myself and try to figure out whether or not I got my money’s worth. In the end, I realized I started the boot camp with nothing more than an understanding of SQL, and ended with the knowledge and experience of putting machine learned models into a production environment. Beyond that, I gained experience working with a variety of popular coding languages like JavaScript, Python, and SQL. I created a lot of interactive visualizations, honed my presentation skills, and collaborated with peers to design git merging strategies and workflows.
A couple months into the bootcamp, our student coordinator invited our cohort to the quarterly meetups at which alums present their best work to their peers and local recruiters. I remember seeing some pretty cool projects and meeting some brilliant people, but I always had the same question when looking at their work: How do you make money from this? I understand not everyone thinks this way, and that everyone has their reason for pursuing a particular topic; however, that question was burned into my mind as I approached my final project. I not only wanted to build fancy machine learning models, but also wanted to approach them from a business perspective instead of an academic perspective.
With my mind made up, I approached my team with the idea of creating a recommendation engine. They thought the idea sounded great and we all began speculating on topics. We sifted through a lot of datasets for potential ideas and eventually settled on analyzing a collection of 130,000 wine reviews.
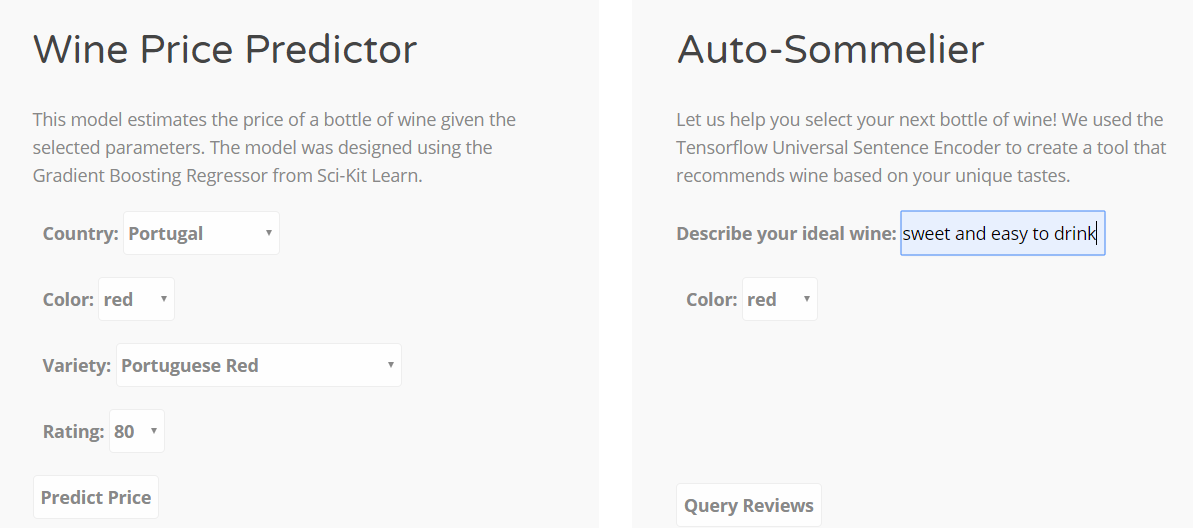
We only had eight days to complete our project. The original idea was to create a tool in which a user could enter a query that describes their ideal wine, and then our model will spit out recommendations; we were an ambitious bunch! Unfortunately, after a bit more research and a couple discussions with our professor, we learned the complexities of training a neural network for natural language processing might be beyond what we can accomplish in the allotted time, so we scaled the project back and decided to build a model that predicts wine prices. Regardless of the difficulty, I never gave up on our original idea and sought a less-complicated way to turn my ideas into tools.
As a student of rhetorical theory and technical communication, I became fascinated with natural language processing when I came across the topic a few years back. To me, the complexities and subtleties of our communication are a defining factor in what makes us a distinct and intelligent species. Training a machine to understand language transforms communication from something that seems so organic, persuasive, and soulful into a something mechanical, ordered, and predictable. For better or worse, I see a lot of potential in the field and wanted to push myself into figuring it out. I spent a few hours researching tools and came across Tensorflow’s Universal Sentence Encoder (USE). It is a pre-trained language processing model. I read through a bit of documentation and decided to use it as a mechanism for accomplishing our initial idea.
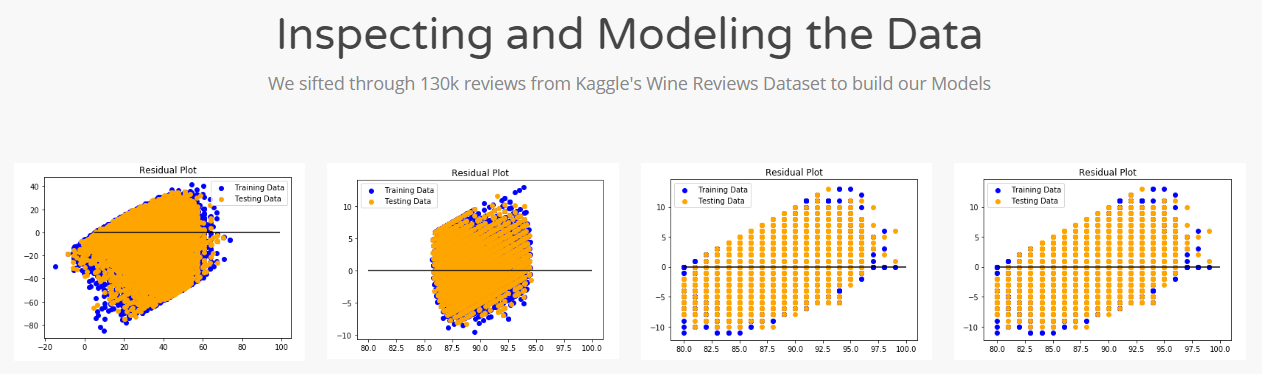
Following a few examples, I quickly coded up a prototype in python and showed it off to the group. It blew them away! With a functional prototype representing our original idea, I shifted gears and began focusing on developing a price prediction model. Since there are so many machine learning algorithms to choose from, we split the workload and each worked on a model. They explored various models such as linear regression, random forests, and deep learning while I dug into Scikit – Learn’s ensemble, Gradient Boosting Regressor. After tuning my hyper -parameters, our model produced an R^2 of .49 and a Mean Absolute Error of 9.14. This told us that our features weren’t able to predict the price of wine very well, but they were close enough to be used as estimates. Several factors that influence the price of wine such as age and winery were not included in our model. Given more time, perhaps those are things we could have included.
With our price prediction model figured out, I put my focus back onto our recommendation engine. Although it took a few iterations to overcome minor performance hurdles, I successfully used the pre-trained model to output recommendations based on the dot product (linear algebra) of the encoded user query and the encoded wine reviews. With the functions figured out, the next challenge was to figure out how to host the models on our website. I began writing a flask app in python.
Beyond the performance issues with the recommendation engine, the second biggest challenge was putting our price prediction model into production. I had to decide how to handle the non-numeric values. Since the machine learning algorithm requires our data be numerical, I needed to figure out the best way for users to select words from a drop list, yet pass numbers into our model. I decided to assign all of our text-based categorical values a numeric value. Then I saved all of the values to our dataset instead of using a function that encoded them on the fly. I figured doing it this way would reduce the risk of a performance bottleneck.
A few late nights and countless iterations later, we successfully built a web page that hosted two working models in less than two weeks time. My team was fantastic at encouraging each other and staying positive. It was a crew of intellectually bright and lighthearted individuals that came together to produce something great, and for that I’m extremely thankful. Although it was beyond the scope of the project, the next step is to figure out a way in which we can host the tools we developed so users from anywhere online can play with them and figure out what wine to try next.


Links to my notebooks:
https://github.com/bendgame/WineRecommend/blob/master/Create_Wine_Recommendations.ipynb
